


Lets dive into a high-level explainer on how you can use TypeScript to chat with a document. For this, we'll be employing two main tools: OpenAI and Pinecone.
We'll have 4 main steps that I'm going to walk you through:
-
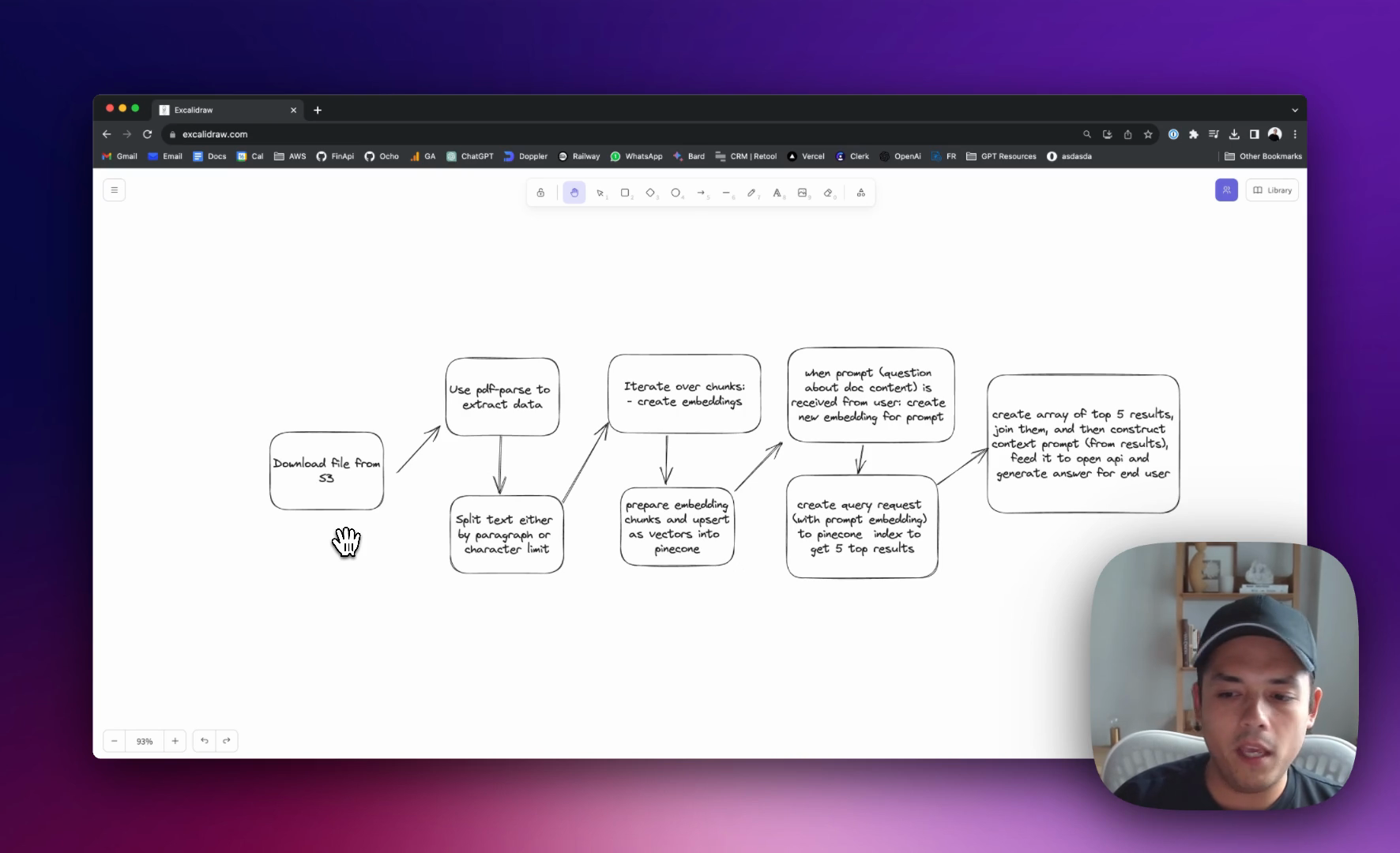
Document Setup: I've got a social media study in PDF format, about 75 pages, stored in S3.
-
Data Extraction: We download this document and use a library called
PDF parseto extract its data. This data is then split by paragraph or a set character limit. We also have logic to remove any chunk that's 10 words or less because, let's be real, there's not likely much meaningful information in such short snippets. -
Creating Embeddings: We then iterate over these chunks to create embeddings. I'll deep dive into what embeddings are in a more detailed video soon. These embeddings are prepared and upserted as vectors into Pinecone.
-
Interacting with the Document: When a user poses a question, we craft a new embedding from that prompt. This is used to create a query request which is then sent to the Pinecone index. Pinecone returns the top five results. We construct a context prompt from these, feed it to OpenAI, and obtain a response to present to the user.
I've set up two endpoints in Postman that will interact with this document AI:
- Summary: This endpoint processes the document, splits the text into chunks, and upserts the data into Pinecone.
- Chat: Using this, we can ask questions against our processed document. It grabs a user's query, makes an embedding, and fetches the top results from Pinecone to generate a relevant answer.
Transcript
Hey everyone, super excited to finally getting around to do this. I've been wanting to do some learning in public in video format. In the past I've created YouTube videos and tutorials in places such as Egghead and I'll probably do a longer format video for this but anyways just gonna dive right into it. This is a
very high-level explainer of how you can use TypeScript to chat with a document. We're gonna use two tools to do that. We're gonna use OpenAI and we're gonna use Pinecone. I'll skip basically talking about or going in-depth in this
video. I'm gonna probably create another video for YouTube which is a longer format and I'll dive deep into the code for that. But for this one we'll keep it short, high-level. We're gonna do three things. We're going to one is go through this chart of everything I have right now. I'm gonna explain what the two
Postman endpoints that I've built and then kind of just dig a little bit through the code but very high-level. Right so I have this thing that I've kind of set up here and the first thing we're gonna do is by the way you can get the file however you want. I just already had a files in S3. I have some social
media study that I found online PDF format about 75 pages long. I've put that in S3. Then what we're gonna do is we're gonna download that and we're gonna use a library called PDF parse to extract the data. Once we've extracted the data from this document we're gonna split it either by paragraph or character limit
and I have some logic there to like remove things that are 10 words or less because what let's be honest there's probably nothing meaningful there. Also then we're gonna iterate over the chunks that we've created in this step and we're gonna create embeddings. Again I'll explain later in a longer format video what embeddings are if anyone wants to know. But then we'll prepare those
embeddings and upsert them in as vectors into Pinecone. Then once the user comes around and ask the prompt or a question we're gonna create a new embedding from that prompt and we're gonna use that to create a query request and send it to the Pinecone index. Once it's in the Pinecone index, Pinecone is going to
return us the five top results. We're gonna create an array of those top results. We're gonna join them and construct like a context prompt, feed it to OpenAI and generate a response for the user. Again it's basically chatting against the documents using the documents as a database. So quick
explainer here, I've created two endpoints that I have in Postman. One is called summary and the other one's called chat. I've kind of built this question that we're gonna use. So the first question or the first step, the first endpoint here is gonna create the chunks and then create the
embeddings and insert them into Pinecone. So we're gonna hit send and basically just quickly through the code what it's doing here is it's grabbing the file, the socialmedia.pdf from my S3, summarizing it. It's not really summarizing per se but it's creating chunks, splitting the text and
upserting that into Pinecone. Then, please ignore this TS ignore, I'm just doing this very raw, we're gonna have a chat endpoint which is what's gonna be able to ask questions against this. And what this endpoint is gonna do is it's gonna grab that question that the user made, it's gonna create an embedding, then
it's gonna basically write against everything that's in Pinecone to try to get a result, get the five top results and return them back, which we're gonna construct a prompt from that. We're going to basically give it a very high-level instruction prompt like answer the question sincerely, if you don't know
the response just reply I don't know. We're gonna provide the chosen text that came back, we're gonna give that as context, then we're going to like add the prompt to the question and then give the answer. We're gonna then grab this constructive prompt that we have here and we're gonna feed it to OpenAI and
then give the answer back to the user. So let's go back to Postman. The process should have been done, it's like super quick. Now we're gonna hit send here and we're gonna ask it a question. What is the impact of social media usage for high school students? So it can take like a couple seconds here, so just bear
with me. Awesome! So the answer that it was or it's basically it went through all of Pinecone and said okay the impact of social media usage on high school students varies, the student found that social media is frequently used by high school students for both educational entertainment purposes etc etc and we
can ask it pretty much any other question we want and if it doesn't know it's just gonna say I don't know. Alright thank you for tuning in, let me know what you think in the comments and if you do want me to provide like the github repo and stay tuned for a longer format video on YouTube. Thank you all!