Understanding API Mocking - Part 3: Mock Service Worker


Now that we talked about the common Request interception algorithms, it’s time to dive deeper into Service Workers and whether they can be used to implement API mocking (spoiler: they can).
Understanding API Mocking Series
This is the last article in a three part series. If you're new here check out the first two installments!



I haven’t listed them in the previous article intentionally because, to my best knowledge, there aren’t many libraries out there using Service Workers for this exact purpose.
But why is that so? What kind of challenges arise when you try to use workers to intercept requests? And is it even possible to solve each and every one of those challenges to get a functional API mocking solution?
To answer all of those questions, we have to start from the beginning.
What is a Service Worker?
A Service Worker is an event-driven background task that can intercept outgoing requests in the browser, modify navigation, and cache responses.
You have certainly heard about Service Workers in the context of Progressive Web Applications (PWA) because they enable essential user experience enhancements like fast client-side caching, offline-first applications, and push notifications.
But, as we will learn, they can also be used for so much more.
Service Worker usage
Every browser ships with a standardized API to declare Service Workers, and here’s what it looks like:
cachesis a global object available in the Service Worker’s scope.
That is an example of a basic Service Worker script for caching resources on the browser level. Now, on its own, that module won’t really do anything. We need to register that worker in our application for it to do its magic.
Note that the Service Worker registration is asynchronous. The browser needs to check if your worker is already registered, compare it to the running version to issue an update, or download the worker script and then register it if it’s a new worker. All that is because worker registrations persist across page reloads to guarantee a better caching experience.
Once the worker is registered, it starts controlling our application—it can intercept, alter, and resolve any asynchronous requests our application makes from that point onward.
Service Worker runtime
You may be wondering when and where a Service Worker handles requests.
The core of any worker is the fetch event listener, which means that something up the chain will dispatch that event. That something is the browser. That’s right, the worker integrates directly into the browser, and the latter notifies it about any outgoing requests that happen on the page.
Despite our application registering the worker, the worker script doesn’t run as a part of the application’s runtime. Instead, it runs in parallel to it.
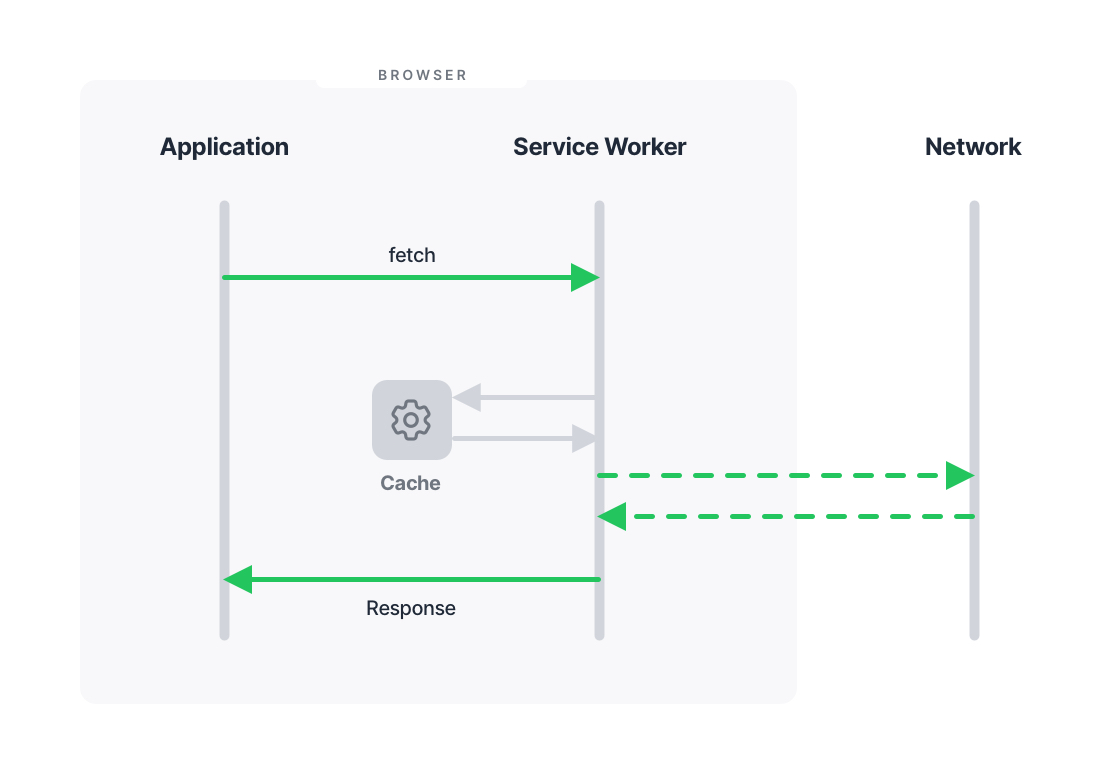
A high-level diagram of the Service Worker runtime.
This characteristic makes the request interception performed by the worker unique because it captures HTTP requests that have already happened and are pending in the browser to be handled by any controlling workers before being sent to the actual server.
What if…?
One of the main use cases for Service Workers is responding from the cache. However, that is not the only source for the responses you can send from the worker.
You might have noticed that in the case of an uncached request, we are sending an original Response instance after fetching the resource:
In fact, the event.respondWith() function just expects a Fetch API Response instance regardless of where we get it from, even if we construct a dummy response ourselves:
The cached responses stored in the global
cachesobject are also plainResponseinstances!
And that custom response will be handled like any other HTTP response in the browser:
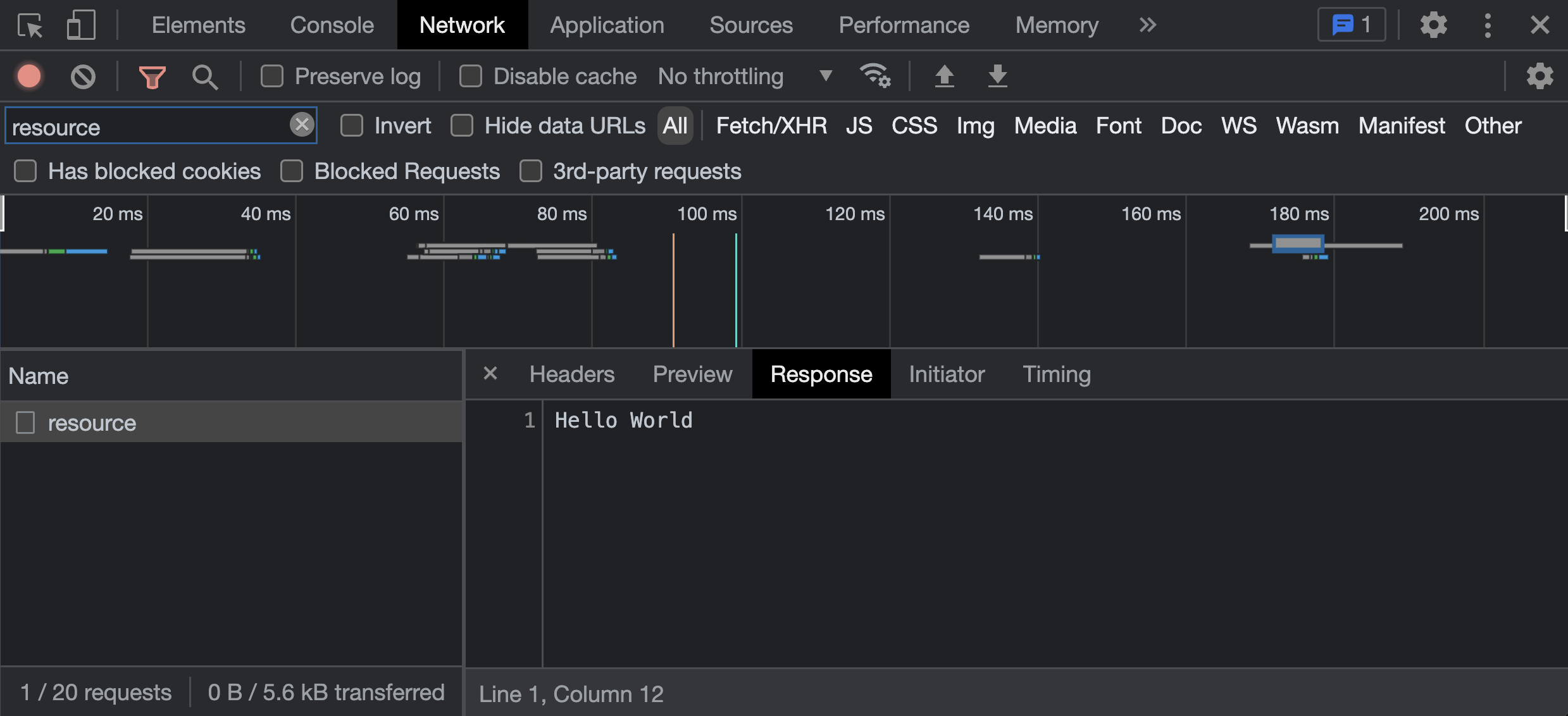
A “Network” tab screenshot showcasing a custom
Responseinstance sent over the network.
Wait, so there’s a standardized browser API to intercept requests on a network level and resolve them with arbitrary responses? That screams API mocking!
Challenges
Well, not that fast. While the Service Worker API is fantastic for many purposes, it wasn’t quite designed with API mocking in mind. There are a number of intricacies in the worker’s behavior that can put spokes in the wheel of our ambition.
Service Worker life cycle
If we decide to put the request matching logic in the worker, we would be modifying the worker script quite often.
But here’s the thing: unless you disable this in the browser’s devtools, any changes to the worker script will only get applied on the next page load when your application’s code loads again and registers the modified worker.
This can easily lead to stale mocking logic, resulting in unreliable tests or confusing development experience. Besides, any changes to the request matching logic, such as appending a new mock scenario for a specific test, would require a full page reload, which further degrades the DX.
Hard-reloading
Remember how I mentioned that workers persist between page reloads? Well, what if you want to opt-out from that? What if you’ve accidentally registered a worker with a bug?
You would want to have that worker force-removed, and the specification comes with an escape hatch to allow you just that.
You see, whenever you hard reload the page, the browser will forcefully unregister any active Service Worker controlling the page. So, if we implement API mocking using the worker, a hard reload will disable any mocking altogether until the next page reload.
That is not ideal, to say the least because it can easily lead to unpredictable behavior both when developing and testing our application against mocks.
Scope
Any Service Worker registers at a specific scope (by default, its the worker’s location on the server and all nested child paths there).
This is great for controlling cache from different parts of the application but not so great when it comes to API mocking.
You see, the worker persists not only between page reloads but also between browser sessions.In other words, it gets registered in the browser and stays there until the same site either updates the worker or unregisters it.
Given that a lot of applications are developed on the same localhost port, this would mean that a mock Service Worker would still affect the traffic between different projects if you decide to spin them up on the same port.
That sounds like a recipe for confusion.
Browser timeout
Service Workers get terminated by the browser if they’ve been idle or too busy for too long.
It would be rather unfortunate to lose the API mocking superpowers if you’ve been focusing on a different part of your application for some time. That time differs between browsers but most seem to implement the pruning of idle workers in one way or another.
Mock Service Worker

Despite the challenges, five years ago I became interested in using Service Workers for API mocking. This led to an open-source library I created called Mock Service Worker (MSW).
MSW has become one of the most widely used API mocking solutions in JavaScript, helping hundreds of thousands of developers prototype, debug, and test their products. It's even been adopted by companies like Google, Microsoft, Amazon, Vercel, and countless others to ensure network control in their CI pipelines.
But MSW's innovation doesn't stop at its interception algorithm. The key design principles of the library are what really sets it apart from the rest.
Ready to pick up the pace?
Enter your email and receive regular updates on our latest articles and courses


We're here to help.
Sign up for our FREE email course
- ⭐️ Portfolio Building: Learn how to build a badass developer portfolio so you can land that next job
Key principles
🤝 Seamless
From day one I wanted to build an API mocking solution that wouldn’t ask you to do any changes to your application.
Not during tests, not ever. Let it request the same production resources but get mocked, defined responses back whenever you need them. Let it evaluate as much of your production code as physically possible, which meant no patching of window.fetch or meddling with the request clients your application may use, while still giving you full control over the network.
🌐 Agnostic
Achieving that level of seamlessness requires being fully agnostic.
MSW works equally well for any request clients, including window.fetch, Axios, React Query, or Apollo, without requiring configurations, adapters, or plugins. Moreover, MSW provides the same predictable behavior regardless of whether it is used in the browser or in Node.js.
This environment-agnostic approach enables MSW to work seamlessly with any tooling that you may use while working on your project, including Storybook, Cypress, Playwright, Jest, Mocha, and more.
♻️ Reusable
API mocking is often considered a feature of testing frameworks, but this significantly limits its capabilities.
To fully benefit from API mocking, it should have its own layer in your application, separate from the tests and tools you use. This way, you can have a single source of truth for network behavior and integrate it wherever you need, giving you total control of your network across the entire stack.
Simply describe mocks once and use them anywhere.
Using Mock Service Worker
Alright, that was a nice prep talk, how do you actually use the library?
While I will walk you through the library usage below, we have an official Getting Started tutorial that I highly recommend reading while integrating MSW into your project.
1. Describe the network
We start by describing the network behavior we want by using request handlers. Those are functions that are responsible for two things: intercepting requests and resolving their responses. Think of them as of server-side route handlers because, effectively, you’re describing server-side behaviors when writing API mocks.
Here’s an example of a handlers.js module that describes how to handle some requests:
MSW ships with first-class support for mocking GraphQL API! Say goodbye to mock providers and embrace silly-fast prototyping by combining multiple API types at the same time.
A module like handlers.js is a great place to put the “happy paths” of your applications—HTTP transactions applicable at any level of your app. We can add new handlers or change the existing ones later on via the [.use() API](https://mswjs.io/docs/api/setup-worker/use), both on browser runtime and on a per-test basis in Node.js.
2. Integrate into environments
Notice how we didn’t take into account where our handlers will run or what request clients our application will be using. Because we don’t need any of those details to describe the network. Now, once it’s described, we can proceed with creating integration points.
With MSW, you can integrate your network behavior with any browser and any Node.js process, including at the same time!
Browser integration
In the browser, MSW operates by registering and activating a Service Worker.
Since Service Workers can intercept and affect outgoing traffic, it’s a security requirement that you host and serve the workers by yourself.
The library ships with a handy CLI to help us copy the worker script into our application’s public directory:
Depending on the framework you’re using, that public directory may be different. Please consult your framework’s documentation to find the correct public directory path to use.
This will copy the ./mockServiceWorker.js script into ./public, so it’s publicly served from the application’s root. This step is only necessary when creating the browser integration.
Next, we have to register that worker. The library exposes a handy setupWorker API to set up and automatically register the worker script we’ve just served:
The setupWorker function configures the worker instance but doesn’t actually register anything yet. You can reuse the same worker instance across different browser processes, such as local development or an end-to-end test in tools like Cypress or Playwright.
To actually register the worker and enable API mocking, we have to call the .start() method on the worker:
Note that registering a Service Worker is an asynchronous action. Because of that, you may encounter a race condition between the worker’s registration and some of the requests your application performs on initial render. To account for those, I recommend deferring your application’s render.
With this integration done, if we load our application in the browser, we will see a console message confirming that API mocking has been enabled:

Any outgoing requests that match the request handlers we’ve defined in handlers.js will be intercepted and resolved using the mocked responses we specified. You can observe the traffic in the “Network” tab in the devtools as you would do with real responses because, as far as your application is concerned, those are real responses.
Node.js integration
There are no Service Workers in Node.js. As the result of it, we don’t have to copy any scripts or account for any asynchronous registrations. Instead, MSW provides the setupServer API that has the same call signature as setupWorker but is meant to provision request interception by the means available in Node.js (I talked about those in the Interception algorithms so feel free to learn more about those).
Note that despite the name, the
setupServer()function doesn’t establish any servers. The name has been chosen for familiarity because, conceptually, you are describing a server-side behavior when using API mocking.
In a similar fashion, this configures the server instance to be reused across any Node.js processes (e.g. Node.js server development, testing frameworks like Vitest or Jest, React Native, etc).
The remaining step is to enable the mocking by calling server.listen(). Below, you can see an example of integrating MSW in Vitest/Jest (which are Node.js processes running your tests):
Learn more about the
setupServerAPI in the Documentation.
Using Service Worker for API mocking
At the beginning of this article I talked about how the Service Worker API isn’t designed for API mocking and that, despite its objective benefits, it poses a set of challenges to bend it to this particular use case. If that’s true, why am I advocating for this tool called MSW?
Because it successfully solves those challenges and has been shipping an incredible mocking experience to developers for years now. Let’s dive into technical details on how exactly it did that.
Writing mocks on the client
In my first iteration of the library, I kept all the request handlers directly in the worker script. That has proven to be a bad decision on many levels:
- You cannot use any third-party code. The worker’s scope is strict and you’d have to bundle the worker if you wish for it to include that code, which is an unnecessary overhead;
- You cannot use your own application’s code, like utilities and helper functions, in the request handlers for the same reason as above;
- Changes to the request handlers (i.e. to the worker) doesn’t apply on the page immediately. You have to wait for the worker update to be promoted, or check the “Update on reload” option in your browser’s devtools and still having to reload the page for the changes to take effect.
Those are developer experience regressions I don’t wish to ship. Naturally, something has to be done about this, and the solution has once again led me to “use the platform”.
I moved the request handlers (including the mocking logic) to the client side. This allows you to use your preferred languages, dependencies, and utilities to describe the network without burdening the worker.
The entire request handling and response resolution pipeline is executed on the client, while the worker simply acts as an intermediary for captured requests and mocked responses. MSW establishes a MessageChannel between your application and the worker that allows the two to communicate effectively.
Here’s how this approach translates to the HTTP request journey:
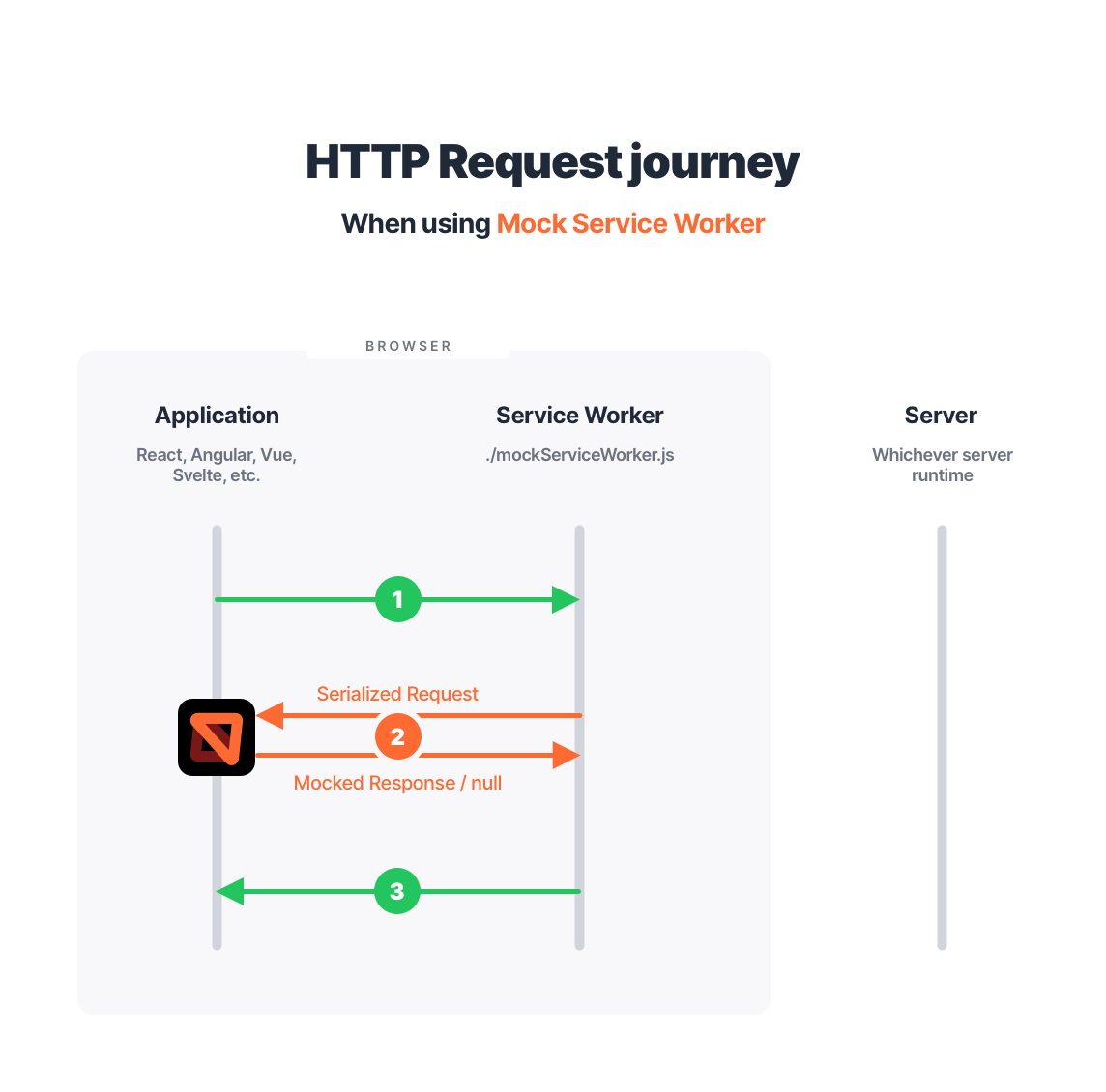
Notice that both the outgoing request (1) and the incoming response (3) are green, which means they are performed and received identically to production. Using a Service Worker means having no request client stubs and sending authentic responses from the network as if an actual server has sent them.
This separation of concerns has clicked with me immediately because it provided me exactly what I was looking for: an interception algorithm that respects your application’s integrity. Moreover, by separating the concerns between the worker and the client, MSW is able to ship a snappy and reactive experience not affected by lazy worker updates or the worker’s life cycle phases.
Handle hard reloading
If you hard-reload the page, the browser will deactivate any workers controlling the current client. For MSW, that would mean deactivating any mocking and, potentially, breaking your app (e.g. when you’re developing mock-first).
Luckily, there is a reliable way to detect when a hard reload happens specifically in the context of a worker. First, a bit of terminology:
- A worker registration (obtainable by
navigator.serviceWorker.getRegistration()) **is an entry kept by your browser that associates a particular client (e.g. a web page) with a particular Service Worker registration; - A controller (obtainable by
navigator.serviceWorker.controller) points to the Service Worker instance that is currently controlling this client.
When a hard reload happens, the browser forces the client to become uncontrolled (navigator.serviceWorker.controller === null). However, hard reload has no effect on the existing worker registrations. That’s why on the next (regular) reload of the page, the matching registration will activate the worker and promote it to become this client’s controller.
Handling hard reload becomes a matter of detecting when that happens and forcing a regular page reload to skip the uncontrolled phase altogether:
Self-terminating Service Worker
Now, when it comes to dealing with the worker’s scope, we certainly don’t want for one set of request handlers to leak to a completely different application served on the same local host. The way we handle this in MSW is by telling the library’s worker to unregister itself when the last controlled client is closed.
This solution consists of two parts:
- Client-side: Detecting when a controlled client is closed and signaling that to the worker;
- Worker-side: When the number of clients reaches zero, unregister the worker.
If you’ve used Service Workers before, you may know that you can unregister the worker from any controlled client by obtaining the worker reference and calling worker.unregister(). However, you can also do that from the worker itself.
Here’s a rough example of the implementation for this solution:
Whenever you close the last page of your application, the worker will unregister itself. Opening a new application on the same host will have no worker present to control that host, giving us the clean state that we want.
Keeping the worker alive
While developing, you may not be touching API-related functionalities for some period of time, and the worker may become idle. To prevent the browser from unregistering such idle worker, MSW implements a pingpong messaging between the client and the worker so it constantly handles incoming events.
Benefits
The main benefit and also the main distinction of MSW is that it embraces API mocking as a standalone layer of your application.
Mocks first, integrations later—that’s been the recipe that has unlocked previously unseen reusability where you don’t have to repeat yourself describing the same network behaviors across different tools that don’t understand each other.
And if you’d like to see how MSW compares to other solutions, we’ve got a Comparison page just for that.
With the option to reuse mocks and less amount of setup needed as a result, you aren’t just adding another library to your stack but investing into resilient, lasting solution that can support you from the early prototype to the finished product.
Frameworks, languages, and libraries may come and go, and you wouldn’t have to make any changes to your API mocking layer (yes, I suggest you start calling it that!).
If you’re still unconvinced, I highly recommend watching the “Beyond API mocking” talk by me and reading through the “Stop mocking fetch” article by Kent C. Dodds.
Closing thoughts
MSW has already revolutionized the experience behind API mocking, and it will only push it forward with each release. Its features, such as behavior-driven network contracts, seamless integration, and the ability to alter your network as you please, are often taken for granted until you switch to another tool.
I would like to finish this piece by saying thank you to Egghead for giving me this incredible opportunity to write about API mocking and MSW, in particular. And thank all of you for reading through this series, trying my projects out, giving feedback, and supporting me throughout the years. You are truly awesome, and I wish to share more exciting things with you in the months to come!
If you believe in seamless, reusable API mocking that respects your application’s integrity, please consider supporting MSW on GitHub Sponsors at https://github.com/sponsors/mswjs. Every contribution helps us bring the future of API mocking closer to reality. Thank you!