Understanding API Mocking - Part 2: Request Interception Algorithms


A humble reminder that in this series we’re learning the nitty-gritty of how API mocking libraries work. Although you’re unlikely to use this knowledge directly (well, unless you decide to write such a library!), it’s still crucial to understand how these libraries work so you could reason about their advantages and disadvantages whenever you come to use one.
Understanding API Mocking Series
You're currently reading part two of Artem Zakharchenko's "Understanding API Mocking" three part series. Check out part one if you missed it or part 3 if you want a deep dive on MSW.



Now that we know every step that a request goes through, let’s take a deep dive into different ways of implementing API mocking.
The interception of requests is at the core of any API mocking solution. Despite there being dozens of libraries to choose from, they all implement one of a few possible algorithms to enable request interception, and those algorithms are directly connected to the request journey.
Today, we are going to take a detailed look at those interception algorithms for both browser and Node.js, learn how they work from the inside, and compare their pros and cons to see how they differ and what price you pay when adopting one.
Purpose of interception
The purpose of intercepting requests is to allow our API mocking solution to perform the following:
- Know when an outgoing HTTP request occurs in your application;
- Have enough information about the request to perform request matching (to find out which mocked response belongs to which request);
- Respond to the intercepted request in the way that the request client originally expects.
The challenge of request interception comes from the fact that there isn’t a standardized API in JavaScript to achieve it. Thus, historically, developers have been coming up with various ideas on stubbing, patching, or otherwise excruciating native modules to provide the so sought interception.
Before we dive into various interception algorithms, let’s quickly revisit what happens to a regular (non-mocked) HTTP request when it’s performed in your application:
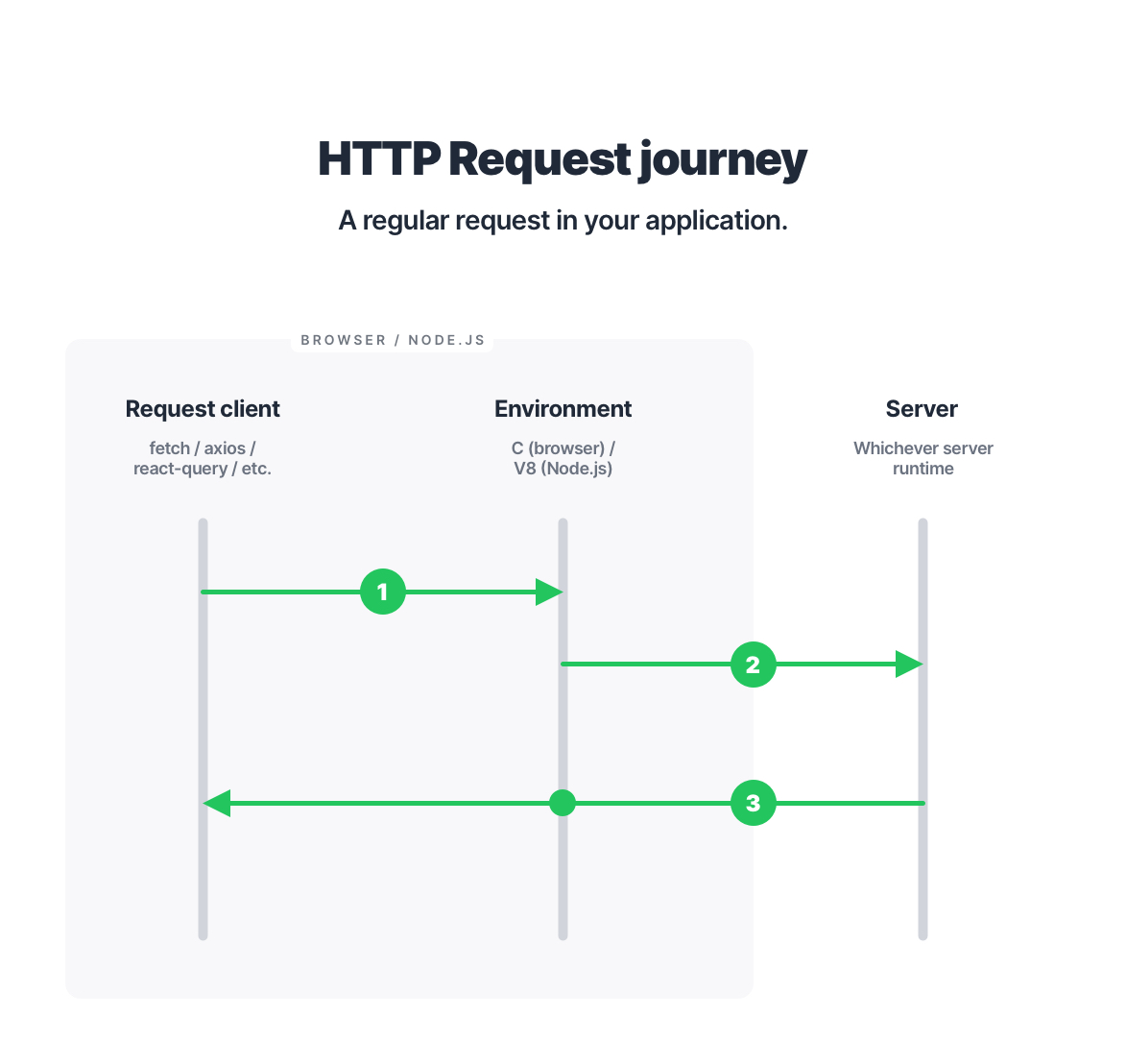
In practice, intercepting an outgoing request comes down to hijacking its journey at a certain point. Based on that point, all interception algorithms can be divided into three main categories:
- Request client-based;
- Environment-based;
- Server-based.
The point at which we decide to interfere with the request journey matters because it provides its own advantages and disadvantages. Let’s take a closer look at those three approaches to request interception.
Ready to pick up the pace?
Enter your email and receive regular updates on our latest articles and courses


We're here to help.
Sign up for our FREE email course
- ⭐️ Portfolio Building: Learn how to build a badass developer portfolio so you can land that next job
Request client-based interception
The most straightforward way to know when a request happens is to detect it on the request client level (i.e. when the request is constructed). This is a common approach for API mocking in the wild, and, given the limitations of the environment, the only approach one may take in the browser (we will learn at the end of this article if that’s truly the case!).
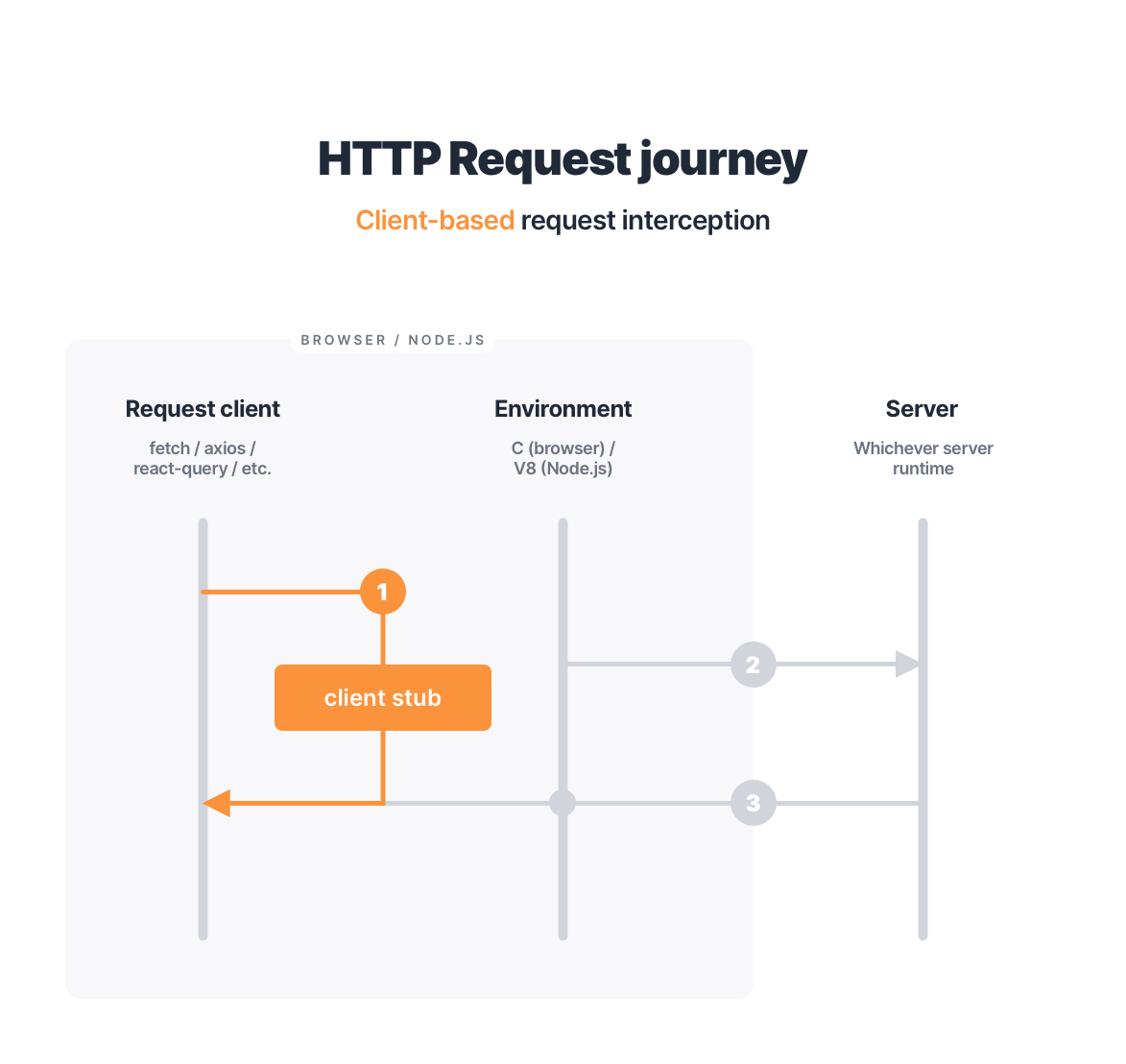
I will be using window.fetch in the browser to illustrate how this algorithm works. Naturally, it’s not limited to the browser, and its principle applies to Node.js as well as any other request client (XMLHttpRequest, third-party libraries, and so forth).
In practice, intercepting requests on the request client level means stubbing that client:
A stub is a fake structure with a pre-determined behavior, such as request interception and matching in our custom
window.fetchfunction. A mock is a fake value, such as the mocked responses we will be constructing later on.
We’re replacing the native window.fetch with our own function, which lets us know whenever a call to window.fetch happens. Since we now, basically, control the fetch, we can do whatever we want with each request. And what we want in the context of API mocking is to resolve certain requests with mocked responses.
I will extend the example above to include a basic request matching so that it would respond to a GET /movies request with a fake list of movies.
Whenever our application performs the GET /movies request using fetch(), it will receive a mocked response instance instead of actually performing that request:
This is a very primitive illustration of the request client-based API mocking. We can improve quite a few things about it, like moving the hard-coded request predicate outside, wrapping the whole logic in a consumable API, and generally making it more versatile to suit different use cases. But I would like to focus now on the benefits and drawbacks of this particular approach.
Check out Debug HTTP with Chrome DevTools Network Panel by Mykola Bilokonsky to become more familiar with HTTP requests in the browser and better understand the ways in which our applications exist in a connected context.

- Examine AJAX Requests with Chrome Devtools
- Analyze HTTP Requests and Responses with Chrome Devtools
- Filter Requests in the Network Panel in Chrome Devtools
- Test Slow Network Performance with the Chrome Devtools
- Analyze Overall Network Traffic Using Overview Tool in Chrome Devtools
- Understand HTTP Status Codes with the Chrome Devtools
Benefits of the request client-based request interception
Benefit #1: Simplicity
The client-based interception is the most straightforward approach since the request client itself has the highest level of context on the HTTP request journey. All we need to know to make it work is the input and the output of the request client (i.e. its call signature). As long as our algorithm complies with that signature, we get a functioning API mocking.
Taking window.fetch as an example, as long as we supply a correct input (input and init arguments of the fetch function) and return the correct output (the Promise<Response>), our algorithm is guaranteed to be compatible with the standard fetch implementation. This puts minimal overhead on this algorithm in the context of accounting for internals, such as request client implementation details or specifics of the environment where it’s being used.
Benefit #2: Performance
The client-based interception is also rather performant since we introduce the stubbing logic at the very first step in the request journey. In other words, only the actual public API of the request client gets called—everything after that is our own mock implementation. This may be beneficial in mock-heavy applications but do bear in mind that it comes at a high price (later on that in the drawbacks).
Benefit #3: Context
Basically, you must’ve noticed already that all the benefits of this interception approach come from it being way up in the request chain. Naturally, this also means that we have the most context exposed to the implementation of this algorithm. And the more information about the outgoing request our algorithm has, the more feature-rich and versatile it can get. This will become more evident once we dive into environment-based interception where the request client context is often coerced or lost altogether.
Drawbacks of the request client-based request interception
Drawback #1: It’s request client-specific
The client-based interception is, by definition, bound to the particular request client. In the example above, we’ve implemented the interception for requests made via window.fetch, but that will not affect the requests made with XMLHttpRequest. Now, think about these two as any two other request clients you may be using: fetch and Axios, Apollo and XMLHttpRequest, etc. Different request clients co-existing in a real-world application is not an unusual thing. But as each client is different, we’d have to implement interception for each and every one of them, respecting the specifics of how they declare and handle requests and responses. Needless to say that such implementation is highly brittle and doesn’t scale by design.
However, common ground can often be found. For example, we may concern ourselves only with fetchand XMLHttpRequest to cover any other request client that runs in the browser, as all of them will rely on those primitives. While this is true, fetch and XMLHttpRequest are still dramatically different, so we will write two different implementations to achieve the same thing—to mock an API.
All we’re doing by stubbing a request client is replacing it with a seemingly compatible “fake” implementation. While we may achieve API mocking as a by-product of that, it doesn’t free this approach from a number of other disadvantages.
Drawback #2: We throw away the request client
Since we no longer call the native window.fetch on mocked requests (that’s the entire point, right?), we effectively disregard whichever logic fetch has around making requests. One prominent example of such logic is the request input validation.
In HTTP, you cannot make a GET/HEAD request with a body—that’s simply against the specification. If you try to do so using a plain version of window.fetch, you will get a runtime exception:
Native fetch guards us against making a mistake in our code, which is great. But will that be the case if we use our patched version fetch?
Ouch! We’ve just performed a request that doesn’t make sense but our application was okay with it. Maybe it even got a mocked response back, continuing to work as if everything was normal. But it wasn’t normal. That fetch call is a problem and it will throw in production, crashing the app for our users. That’s not even the worst part. Since we often use API mocking in testing, any test concerning this faulty code will pass because it runs in a fantasy land where requests are not validated before being declared. The fantasy we’ve created ourselves by replacing window.fetch.
A natural thing to say here is that we can add that input validation to our custom fetch and be done with it. Keep in mind that missing request body validation is only a single example of how dangerous it may be to replace native code. Unless you wish to implement the entire Fetch API specification (which library authors certainly don’t want to do), you will always compromise on the application’s integrity whenever a native module like fetch is stubbed.
Drawback #3: Requests never truly happen
Somewhat derivative from the previous point, the lack of the “clean” request client call also means that whichever request intention we’ve expressed with it will never actually happen. You can observe it yourself by looking at the “Network” tab of your browser’s DevTools whenever a mocked request occurs—it will not be there. But do not get confused, the Network is not lying to us here: the request never really happens, we only pretend that it does.
So, the request never happens, why is that a big deal? Although we are mocking things, it doesn’t justify throwing away the parts of our application, and HTTP requests are a rather crucial part at that, don’t you agree? By replacing the request client, our application suffers from the following issues:
- It hurts observability. We can no longer observe the outgoing traffic, be it the browser’s DevTools or any kind of request monitoring tools in Node.js. This may lead to confusion while developing and testing, if not bugs related to other parts of the system reacting to outgoing requests.
- It alters the system. By stubbing the request client, we change our application. What does
window.fetch()do in production? It taps into the browser’s native code. What does it do during automated tests? It hits our mock function, ignoring any underlying browser API whatsoever. That is a deviation, and the more we let our system deviate, the more we’re working with a different system. I illustrate the practical manifestation of this in the previous drawback by showing you how we can perform a completely invalid request in tests and it’d still qualify as passing because our mock doesn’t know better.
I understand that the words “mocking” and “alteration” have become practical synonyms over the years but I’m writing this piece to stir a discussion that they don’t have to be. We can achieve API mocking without sacrificing our application’s integrity (in fact, leaving it entirely intact!) and I will prove this to you over the course of this series.
Environment-based request interception
Since we are talking about request interception in JavaScript, by “environment” I will refer to Node.js as the environment. Although the browser is another major surface where JavaScript can run, its environment is rooted deeply into the browser’s internal and native C code, to which we have no access.
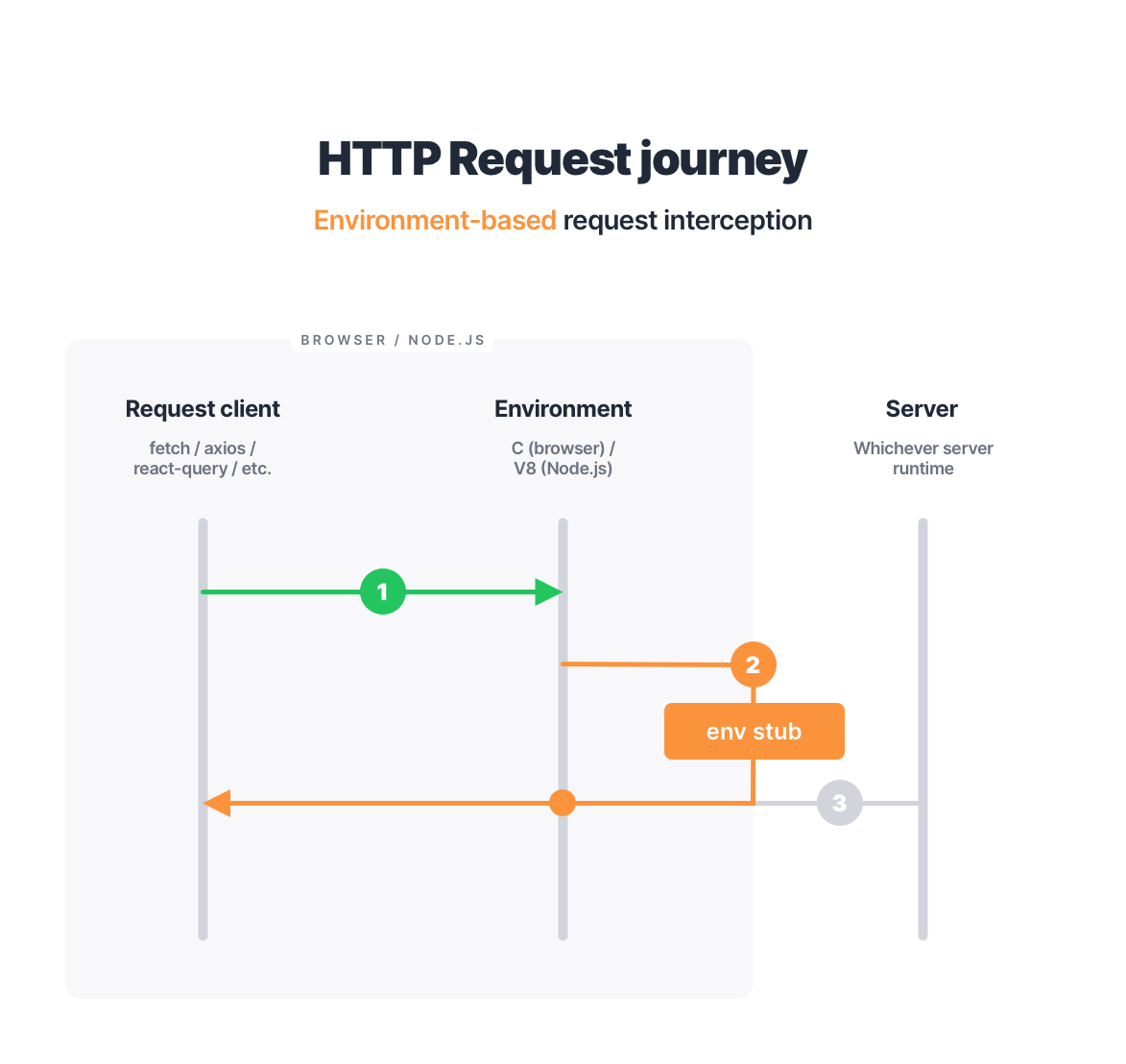
In Node.js, however, the entire runtime is our playground. At least enough so to intercept requests on the level of underlying request-issuing modules, mainly http and https. As we’ve learned in the previous article, any request in Node.js bubbles down to either high-level (http.ClientRequest) or low-level internals such as net.Socket. Naturally, those internal modules become the primary area of implementing API mocking for us.
The most common approach to request interception in Node.js is stubbing the http module or, to be more precise, its ClientRequest class. In practice, this approach is not much different from the one described in the client-based interception above.
Here’s an example of how to intercept HTTP requests in Node.js:
There’s quite a number of things omitted from this example for simplicity’s sake. Even at this scope, it should give you a good overlook that the lower you get in the call stack, the more verbose your implementations become.
The only remaining thing is to import this module anywhere in a Node.js process and it would do its magic, replacing the http.ClientRequest class globally for that entire process. Any subsequent constructs of that class will yield the ClientRequestOverride instance we’re written above.
While the majority of request libraries rely on the http and http.Client, I must stress that there are some that omit that construct entirely, utilizing low-level socket communication to implement the request logic (one of such examples is Undici, which lay in the foundation of the global fetch in Node.js). Obviously, the patched module above will have no effect on such libraries, so we need to account for that in real-world scenarios.
Benefits of the environment-based interception
Benefit #1: More of the request client’s logic gets executed.
Because this algorithm doesn’t meddle with the request client itself and instead replaces the universe in which the client is being run, it allows the client to execute in its entirety. Any built-in logic that the client has, like input validation or response normalization, will be performed just as it would in production, which is great.
Benefit #2: Request-client agnostic.
Applying the interception on the environmental level means that any client will eventually arrive there. This makes environment-based API mocking client-agnostic and, as the result, more versatile when it comes to supporting any request client your application may use.
Benefit #3: More control.
Compared to stubbing the request client, environment-based interception provides the API mocking solution with more control since it’s dealing with a lower-level request code. For example, stubbing the http module allows our solution to tap into the socket connection because it’s available on the ClientRequest level.
Drawbacks of the environment-based interception
Drawback #1: Throwing away the environment
Similar to the stubbing of window.fetch(), doing so with the native Node.js modules means we’re throwing away whichever internal behaviors they have and replacing them with our own implementation. Not only have we now become obliged to adhere to the native behavior of those modules to reduce bugs, but we also need to re-implement some of the vital features, like request validation, because it’s performed when establishing a Socket connection, which won’t happen anymore.
Overall, the environment-based interception is still subjected to the same drawbacks as the client-based one, meaning that the HTTP requests won’t actually happen and that it’s entirely possible to construct a request instance that doesn’t make sense otherwise.
Drawback #2: Getting rather low-level
Despite the ClientRequest class being a high-level API in Node.js, you can already notice how deeper we have to go into this module’s details to implement mocking. For instance, to correctly respond to an intercepted request we need to know that Node.js sets the internal res property of ClientRequest to the response instance (IncomingMessage) and expects an empty response body chunk (null) to be written to the response buffer to indicate a successful finish of the response. If we miss those internal details, our intercepted requests will hang indefinitely without any indication.
This is one of the reasons why stubbing native modules can be dangerous, as the stubs become closely connected with the environment’s implementation of those modules, become aware of their internals, and may get fragile and flaky as the result.
Server-based request interception
Although we cannot affect the request once it hits the server, it doesn’t mean that the server level is not an option to implement API mocking. Surely, we don’t want to reach the actual server but what if our request reaches a mocked server instead?
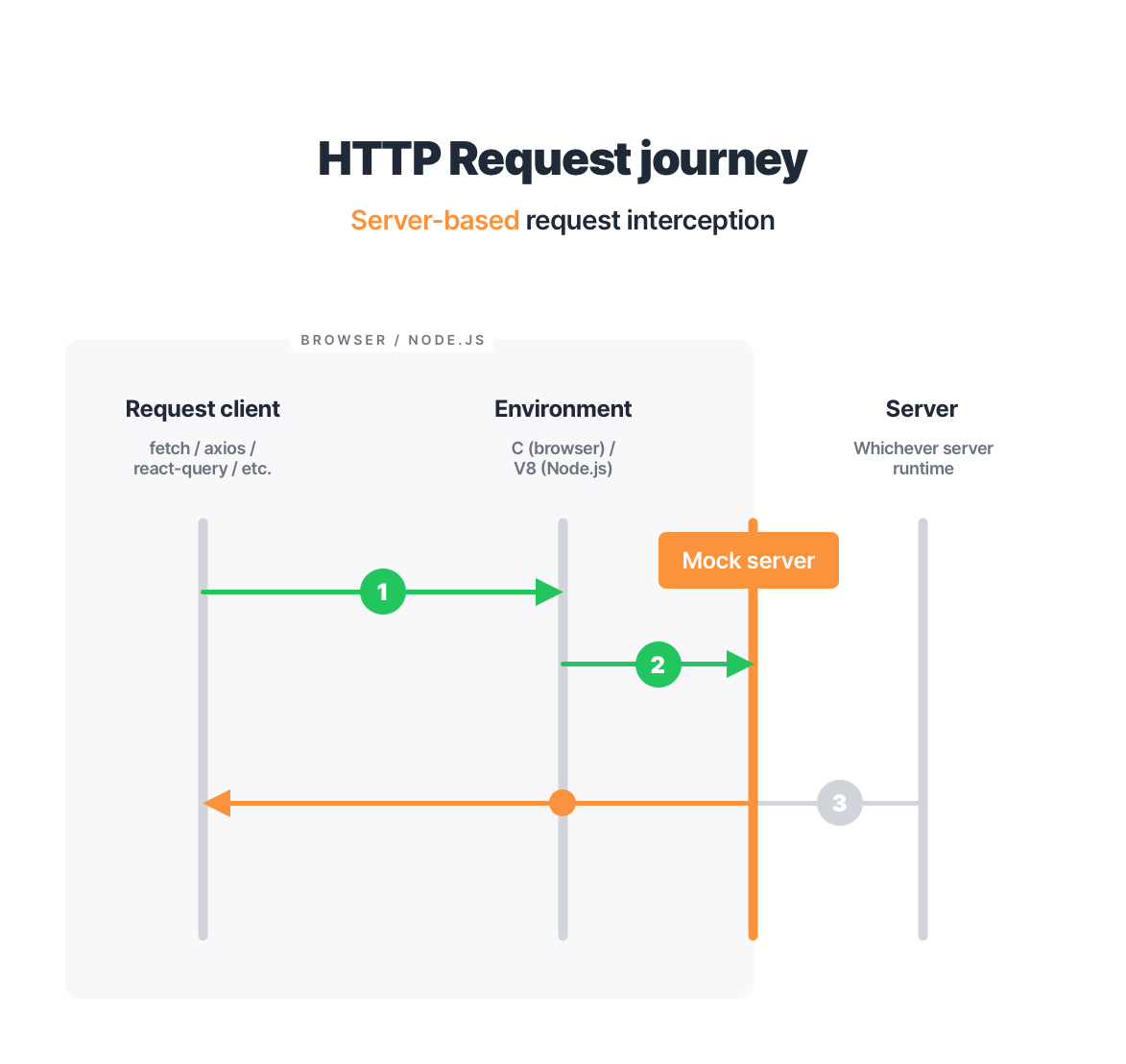
In practice, this means creating that mocked server and integrating it as a part of our testing/development workflow:
All we have to do to make this work is to start the mock server locally and route our application’s requests to it instead of the production server. That sounds fairly straightforward. Now, let’s talk about what this approach implies.
To learn more about how to build an API with Express check out Building an API with Express by Kevin Cunningham!

- Set up Express to Automatically Reload on Save with nodemon
- Return JSON from Express and Handle CORS Errors
- Serve a random static file with Express
- Parse and Process JSON with Express
- Create Custom Middleware for Authentication in Express
- Create custom middleware for authentication in Express
- Handle Syncronous and Asyncronous Errors in Express
- Configure an Auth0 API Authentication to Use with Your Server
- Add Middleware to Validate a JSON Web Token (JWT)
- Get a JWT From Auth0 in Express to Be Used in Authentication
- Create an upload route in an Express API
Benefits of the server-based interception
Benefit #1: Request client and the environment are intact
As the name suggests, the server-based interception focuses on the server, the preceding request client and environmental logic remain intact. We don’t introduce any stubs and we don’t meddle with the request client in any way, which is fantastic!
As a result of this, the requests we make actually happen and are observable in the system.
Benefit #2: Standalone server
Since we’re establishing an actual living and breathing HTTP server, it’s also available in any other context should we need it. For example, we can curl it straight from the terminal or share it with our colleagues on the same network.
Based on these benefits, server-based interception may look like a perfect approach. But before you jump to that conclusion, let’s take a look at its drawbacks because, unfortunately, they are rather significant.
Drawbacks of the server-based interception
Drawback #1: Altering the system
Once again, we circle to the system alteration point. Unlike the previous two approaches where we throw away either the client or the environment, with the server-based interception we’re preserving them both. Well, almost. Since we don’t want to hit the actual production server, we need to direct our requests to the mock server instead, which means changing our intention behind those requests.
Let’s take another look at the GET /movies request from the previous example:
In order for our application to hit the mock server, we introduce the API_URL environment variable as a part of the resource URL so we wouldn’t request actual production resources. Here, there it is—we don’t request actual production resources. Instead, we’re routing all requests to the mock server to handle. In other words, the value of the API_URL variable bring turn our entire application to an alternative universe, and it’d be a universe quite different from the one that runs in production.
The easiest way to demonstrate why this is crucial is to imagine what value API_URL will have in production. It’s probably something like https://api.myapp.com or https:/myapp.com/api. Except, the second URL has a typo in its protocol, which makes it invalid. It’s a rather mechanical mistake, not a big deal, we write tests to help us avoid things like that. But will they help? Well, our requests hit http://localhost:3000 (the mock server) during tests, and that URL is indeed correct. What we are getting is perfectly passing tests and perfectly broken production.
My point here is that you should be extremely cautious when introducing deviations to your system—things that make it behave differently from its “base” (production) state.
The more you alter the system under test, the more you’re testing a different system.
Drawback #2: Writing and maintaining an actual HTTP server
Do not be fooled, despite it being a “mock” server, it’s still an actual HTTP server you have to write and maintain. As with any code, writing the mock server subjects its logic to bugs and inconsistent behaviors, which may result in flaky and unreliable tests. Even if you decide to use third-party libraries to speed up and simplify this process, you will still be doing the same thing just over a third-party abstraction, such as a JSON manifest describing server-side routes.
I like using one particular example to illustrate this. Imagine the request your application makes as a person and the actual server as a bank. Without any API mocking, the (test) person would walk into the bank and perform real operations, which is not desirable in tests. If we use request client-based interception, we’re giving them noodles for arms, altering the human body construction and behavior. The real, production person won’t have those alterations, and so we’re effectively conducting tests on a made-up, seemingly-compatible being, hoping that it passes for humans. Well, what does it make a mock server in this allegory? It’s an entire fake bank we built for the person to walk in and interact with. We’re keeping the real person, no modifications, but everything else around them suddenly becomes fake. The integrity of such a testing setup and the confidence provided by such tests is directly related to the faithfulness of the “fake bank” implementation, which is never entirely complete by design.
Drawback #3: Increased complexity of development pipelines
Any process that depends on API mocking now, be it automated tests or local development, becomes dependent on the mock server. You have to ensure the mock server is up and running and ready to handle requests before you run your tests or start developing. From the technical perspective, you need to spawn the server process in time and in parallel to whichever other process depends on it.
While it may not sound like a big deal, it is a price to pay for this approach nonetheless, especially compared to the zero runtime cost of request client- and an environment-based interception.
Drawback #4: No control over runtime behaviors
Since the mock server and your tests run in two separate processes, there isn’t a straightforward way to affect the mock’s behavior directly from the test. At this point, we need to recall that we’re using API mocking to gain control over the network, so whenever that control suffers due to the implementation details of mocking, it automatically becomes a drawback.
Imagine the following test:
The <Movies/> component always performs a GET /movies request, that’s what it’s designed to do. In order to emulate a 404 response from the mock server, we need to bake in a special logical branch into that route handler on the server. For example, by responding with a 404 when the client requests a certain movie ID:
Instead of collocating the network behavior with the immediate surface that needs it (the test), we’re pushing it to the mock server, which increases its complexity. Because that collocation is not evident, maintaining such case-specific logic on the server becomes challenging. I like putting it this way: ten tests adding per-test overrides are much more efficient than one server handler accounting for ten different scenarios.
Drawback #5: Shared test state.
When using the mock server approach, you usually spawn a single server for the entire test run. This makes the mock server a common dependency between all tests, and it becomes quite easy for it to introduce a shared state, resulting in flaky test results. Allow me to illustrate.
Imagine that the first test performs an unexpected action that crashes the mock server. Respectfully, that test will fail, indicating a problem. But here’s a pickle: the next test will also fail, despite there being nothing wrong with it. Whenever your test fails due to any other factor but the issue in the tested system, you’re getting an unreliable test. Now, what if there were a dozen tests in this test file? Or maybe a hundred? Pin-pointing the actual problematic test would suddenly become a time-consuming exercise.
This happens because all the tests depend on a shared state, that state being the runtime of the mock server. Although this is not as evident as a more conventional shared state issue of multiple tests depending on a single mutable data, the shared state introduced by a test server bears the same consequences on the reliability of our test suites.
Comparison
Now that we are familiar with the main API mocking algorithms, let’s summarize and compare them. To keep this comparison more systematic, I’m going to use the following criteria:
- Request’s integrity. Does this algorithm perform the request at all?
- System’s integrity. Does it alter our system (e.g. makes it request different resources)?
- Runtime control. Does it allow controlling different network behaviors from our tests/application runtime (e.g. introducing behavior overrides on a per-test basis)?
- Maintenance & scalability. How feasible it is to maintain across different request clients and, generally, throughout the project’s life-cycle.
| Client-based interception | Environment-based interception | Server-based interception | |
| Request’s integrity | ❌ | ❌ | ✅ |
| System’s integrity | ❌ | ❌ | ❌ |
| Runtime control (behavior overrides) | ✅ | ✅ | ❌ |
| Maintenance & scalability | ❌ | ✅ | ❌ |
We can see that environment-based interception hits the most boxes compared to alternatives. It doesn’t come as a surprise that this is the most common approach used to implement API mocking in the wild. Pretender, Nock, PollyJS, and almost any other API mocking library you can find utilize the environment to provide request-agnostic and maintainable mocking. That is not a bad approach in itself but it does come with a few disadvantages that I’ve talked about previously in this article.
The request’s and system’s integrity are still crucial characteristics to consider if we wish to minimize the difference between the test and the production system. Historically, these points were overlooked since altering the system was either a technical limitation or a price to pay in order to make the mocking work in the first place. I’m really happy to say that is no longer the case, and we can, and already have API mocking solutions that can preserve the application’s integrity across the entire request journey. To make this pitch even more unbelievable, those solutions are based on standard APIs that are widely supported and have been around for years now. So, what are those exactly?
The “perfect” approach
Okay, I hope I got your attention at this point. But before I reveal the cards, let’s forget about all those approaches, benefits, and drawbacks for a moment. Instead, let’s just focus on how would we describe the “ideal” API mocking solution.
When I sat down to brainstorm this very question in 2018, I came up with a list of criteria such a solution would meet:
- It actually performs requests (no request client or environment stubs).
- It allows requests to hit the same resources as in production (no system deviation).
- It allows controlling network behaviors from the test or application runtime.
- It has no runtime or build-time cost, and a minimal maintenance cost.
- It allows reusing the same mocks across the entire stack (in tests, in local development, in Cypress, Playwright, Storybook, etc).
Now, that does sound ambitious! We used some of these criteria in our comparison today but others, like reusability, we haven’t even mentioned yet. Nevertheless, I like starting from lists like this because they help me focus on what I want and then see what would be the price for having that.
At the first glance, the price to meet all those criteria seems insurmountable. And yet, I began researching the matter, poking around beaten paths but also directions that were rather… unconventional. Until, finally, I stumbled upon something.
Service Worker API
Turned out, there was a standard browser API that introduced seamless request interception to procure response caching. It was the Service Worker API.
Briefly, the Service Worker API revolves around registering a *worker—*a JavaScript module that can intercept any outgoing traffic on the page. What makes this kind of interception unique is that it happens entirely on the network level of your browser after the request gets performed and leaves your application’s context.
To help you understand what a huge difference this makes, allow me to illustrate the same HTTP request journey and where a Service Worker gets to shine:
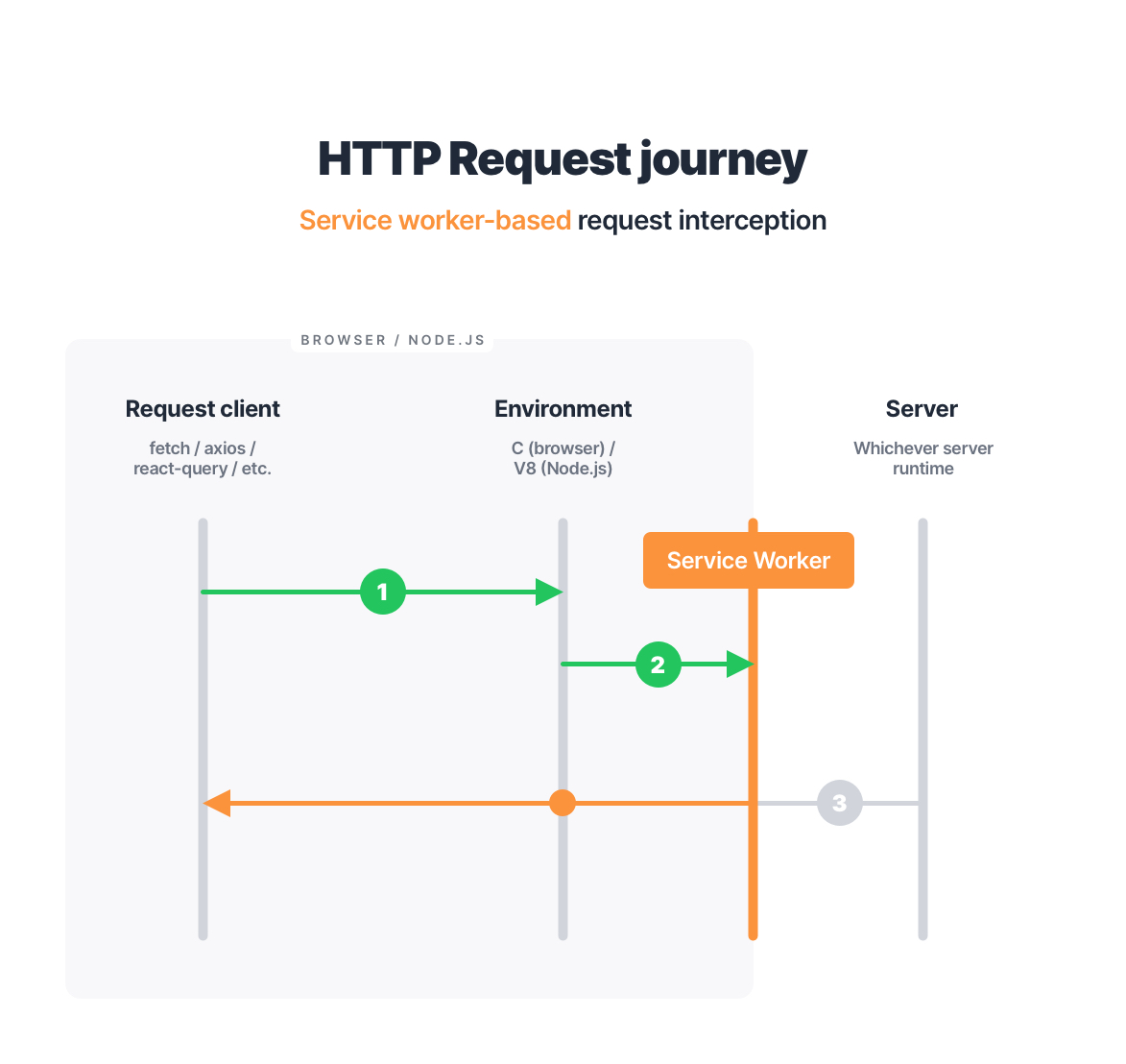
But the Service Worker API is designed for caching, and it would be quite a fit to bend it to the API mocking needs. From the worker controlling unrelated clients to the browser throwing away the worker on hard-reload—there are a lot of challenges to overcome before this API could be utilized for mocking. Needless to say, this is a time-consuming endeavor with no guarantee of success.
Which is precisely why I went with it!
In the next episode
Next time, we will learn how Service Workers can be used for API mocking, talk about the challenges and blockers that imposes, and get a look at a library that has revolutionized API mocking in terms of system integrity and reusability of mocks.
Meanwhile, follow me on Twitter where I post technical tips and tricks around testing in JavaScript and stir occasional discussion or two. See you in the next one!
Check Out The Final Part


